Tracing OpenvSwitch with eBPF

yo kiddo, do u ready to learn about eBPF? but this time it’s not about eBPF but about openvswitch, yep now we doing diehard let’s tracing openvswitch with ebpf.
let see how powerfull is ebpf.
but first let me show my cluster topology,
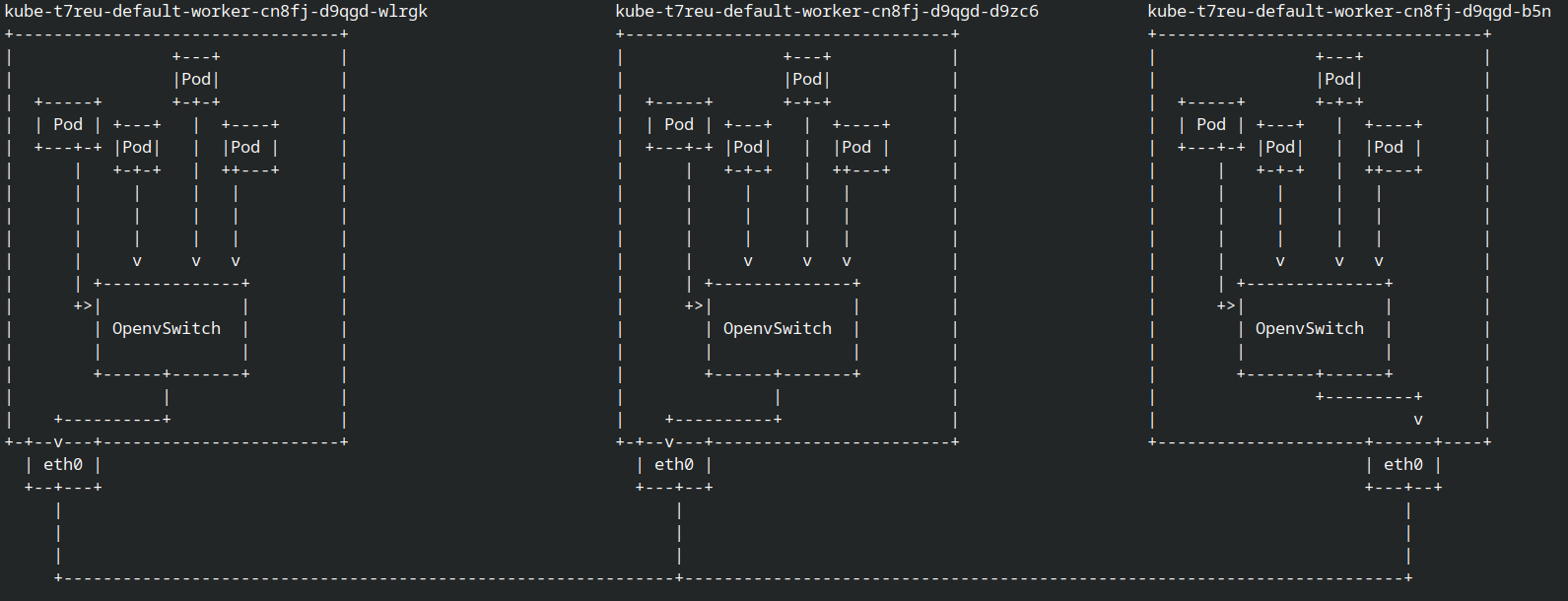
for this time i use kubeovn for the deployer ovs because deploying kubeovn much easy rather than install it on openstack deployment.
as you can see i have 3 nodes, each node have ovs agent and every pods is connected into ovs
sorry but i’ll not explain in detail about my topology. (like how pods connecting into ovs or how ovs communication with other ovs in another nodes, but if u still new about ovs and have some big curiosity you can watch the ovs video by david mahler)
let’s move into the study case.
Probset
if you already experance with ovs in openstack or another cms(Cloud Management Service) you already realize if ovs was not just buch of connected port from vm/pod into big bridge then tunnel it into another node with vxlan or genev.
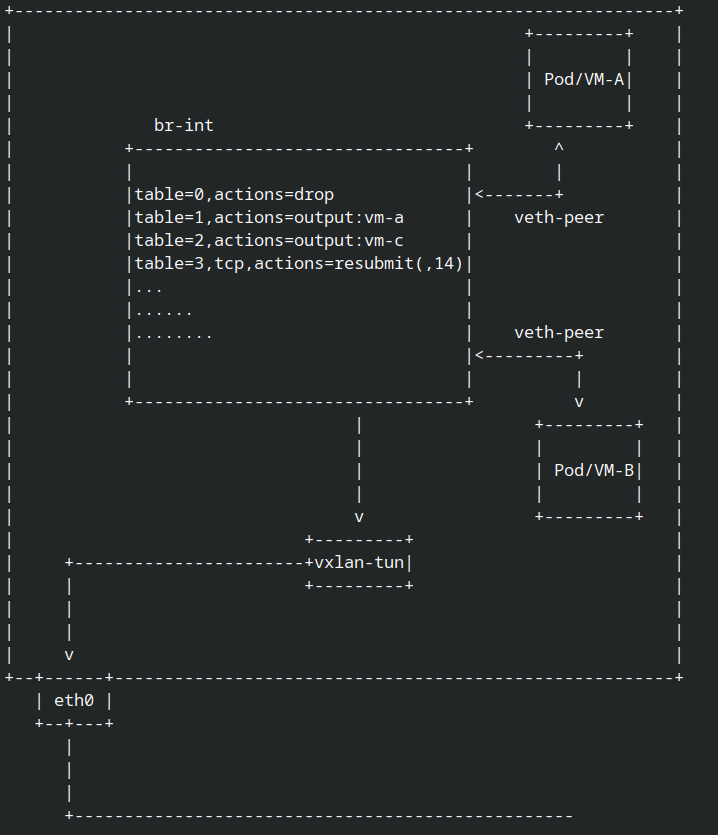
ovs have bridge interface called br-int or Integration Bridge, in this bridge all network flows was running. br-int isn’t not about routing or firewall,but it’s about all network functionality, when i say all yes it’s all of network functionality like routing,natting,firewall,arp spoofing prevention,and much much more
all of network functionality it’s coming from openflow, you can see network flow in br-int with ovs-ofctl dump-flows br-int, from openflow we can create a network flow. i.e: “pod/vm-A was same node with pod/vm-B so no need send the package into tunnel” or “pod/vm-A allow all icmp connection but not udp” or “pod/vm-B try to connect with pod/vm-C but pod/vm-C was not in this node, so let tunnel the request into another node who running pod/vm-C”
ok that just intro, let’s start the probset.
it’s just a simple question, how we know if the network package was not intrupted or droped by openflow in br-int? or can we make sure if the package was sending into tunnel so another node can process it?
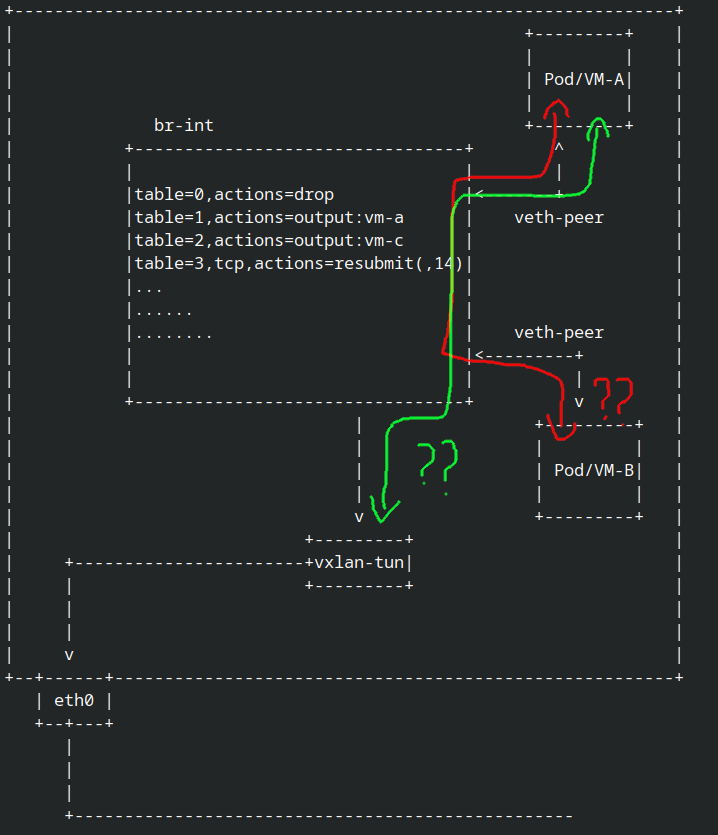
in theory we can Trace it with dump-flows and follow the table and wait until the n_bytes or n_packets was increasing, but yeah that was time consuming and very very hard if the flows already so many.
ebpf
over years I have been troubleshooting with dump-flows,grep,watch,tcpdump tbh that was quite painful, until i saw some question&answer in stackoverflow and from that discussion make my head click like a bulb.
first let check the kernel avability for trace ovs
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
root@kube-t7reu-default-worker-cn8fj-d9qgd-wlrgk:/kube-ovn# cat /sys/kernel/tracing/available_filter_functions | grep openvswitch
mask_ipv6_addr [openvswitch]
ovs_dst_get_mtu [openvswitch]
prepare_frag [openvswitch]
set_ip_addr [openvswitch]
set_ipv6_addr [openvswitch]
set_ipv6 [openvswitch]
set_nsh [openvswitch]
set_ipv4 [openvswitch]
output_userspace.isra.0 [openvswitch]
set_eth_addr [openvswitch]
ovs_fragment [openvswitch]
do_output [openvswitch]
ovs_vport_output [openvswitch]
execute_masked_set_action [openvswitch]
do_execute_actions [openvswitch]
clone_execute [openvswitch]
ovs_execute_actions [openvswitch]
action_fifos_init [openvswitch]
action_fifos_exit [openvswitch]
ovs_update_headroom [openvswitch]
new_vport [openvswitch]
destroy_dp_rcu [openvswitch]
get_flow_actions [openvswitch]
ovs_dp_set_upcall_portids [openvswitch]
ovs_dp_change [openvswitch]
ovs_nla_init_match_and_action.constprop.0 [openvswitch]
ovs_init_net [openvswitch]
ovs_dp_masks_rebalance [openvswitch]
ovs_flow_cmd_alloc_info [openvswitch]
...
.....
......
.......
ok good kernel support to trace ovs, now try trace with stackoverflow refrence.
create the script
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
#include <linux/skbuff.h>
#include <linux/ip.h>
#include <linux/udp.h>
#include <linux/socket.h>
#include "openvswitch-module/vport.c"
BEGIN
{
printf("Tracing ovs_vport_receive rev. Hit Ctrl-C end.\n");
}
kprobe:ovs_vport_receive {
print("test")
}
END
{
printf("OVER bye!!")
}
run it
1
2
3
4
5
6
7
8
9
root@kube-t7reu-default-worker-cn8fj-d9qgd-wlrgk:/# bpftrace ovs-test.bt
Attaching 3 probes...
Tracing ovs_vport_receive rev. Hit Ctrl-C end.
test
test
test
test
^C
OVER bye!!
ok, look like its running, but what is ovs_vport_receive?
let’s see it at kernel tree.
from kernel tree it’s say
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
/**
* ovs_vport_receive - pass up received packet to the datapath for processing
*
* @vport: vport that received the packet
* @skb: skb that was received
* @tun_info: tunnel (if any) that carried packet
*
* Must be called with rcu_read_lock. The packet cannot be shared and
* skb->data should point to the Ethernet header.
*/
int ovs_vport_receive(struct vport *vport, struct sk_buff *skb,
const struct ip_tunnel_info *tun_info)
{
struct sw_flow_key key;
int error;
so ovs_vport_receive? was fuction to handle received package from vm/pod interface? since it’s have sk_buff so we can filter it
let’s create script with filter the icmp protocol
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
#include <linux/skbuff.h>
#include <linux/ip.h>
#include <linux/udp.h>
#include <linux/socket.h>
#include "openvswitch-module/vport.c"
BEGIN
{
printf("Tracing ovs_vport_receive rev. Hit Ctrl-C end.\n");
}
kprobe:ovs_vport_receive {
$skb = (struct sk_buff *)arg0;
$iph = (struct iphdr*) ($skb->head + $skb->network_header);
if ($iph->protocol == IPPROTO_ICMP) {
$src_ip = ntop (AF_INET, $iph->saddr);
$dst_ip= ntop (AF_INET, $iph->daddr);
printf("src_ip:%s -> dst_ip:%s \n",$src_ip,$dst_ip);
}
}
END
{
printf("OVER bye!!")
}
Run it

As you can see after I exec bpftrace and ping the icmp package was printed in bpftrace, since vport struct have net_device struct let’s try to find the interface name and filter it with src ip&dst ip
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
/**
* struct vport - one port within a datapath
* @dev: Pointer to net_device.
* @dev_tracker: refcount tracker for @dev reference
* @dp: Datapath to which this port belongs.
* @upcall_portids: RCU protected 'struct vport_portids'.
* @port_no: Index into @dp's @ports array.
* @hash_node: Element in @dev_table hash table in vport.c.
* @dp_hash_node: Element in @datapath->ports hash table in datapath.c.
* @ops: Class structure.
* @upcall_stats: Upcall stats of every ports.
* @detach_list: list used for detaching vport in net-exit call.
* @rcu: RCU callback head for deferred destruction.
*/
struct vport {
struct net_device *dev;
netdevice_tracker dev_tracker;
struct datapath *dp;
struct vport_portids __rcu *upcall_portids;
u16 port_no;
struct hlist_node hash_node;
struct hlist_node dp_hash_node;
const struct vport_ops *ops;
struct vport_upcall_stats_percpu __percpu *upcall_stats;
struct list_head detach_list;
struct rcu_head rcu;
};
Create the code
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
#include <linux/skbuff.h>
#include <linux/ip.h>
#include <linux/udp.h>
#include <linux/socket.h>
#include "openvswitch-module/vport.c"
BEGIN
{
printf("Tracing ovs_vport_receive rev. Hit Ctrl-C end.\n");
}
kprobe:ovs_vport_receive {
$vport = (struct vport *)arg0;
$skb = (struct sk_buff *)arg1;
$dev = (struct net_device *)$vport->dev;
$iph = (struct iphdr*) ($skb->head + $skb->network_header);
if ($iph->protocol == IPPROTO_ICMP) {
if (($iph->saddr == (uint32)pton("10.16.0.28")) && ($iph->daddr == (uint32)pton("10.16.0.29"))) {
$src_ip = ntop (AF_INET, $iph->saddr);
$dst_ip= ntop (AF_INET, $iph->daddr);
printf("iface_name: %s src_ip:%s -> dst_ip:%s \n",$dev->name, $src_ip,$dst_ip);
}
}
}
END
{
printf("OVER bye!!")
}
Run the script

we can see now bpftrace print the interface name and src&dst pkt in detail.
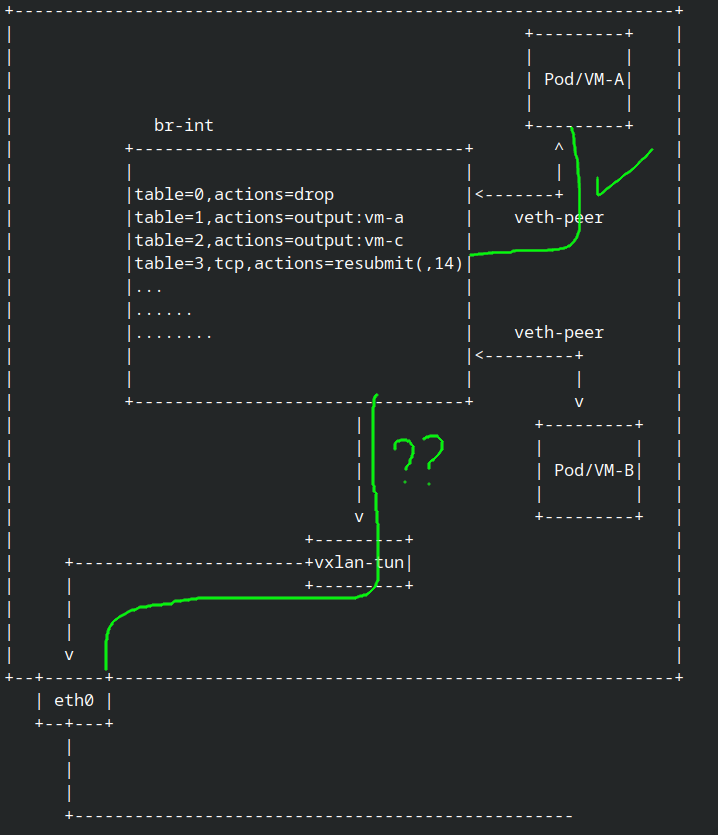
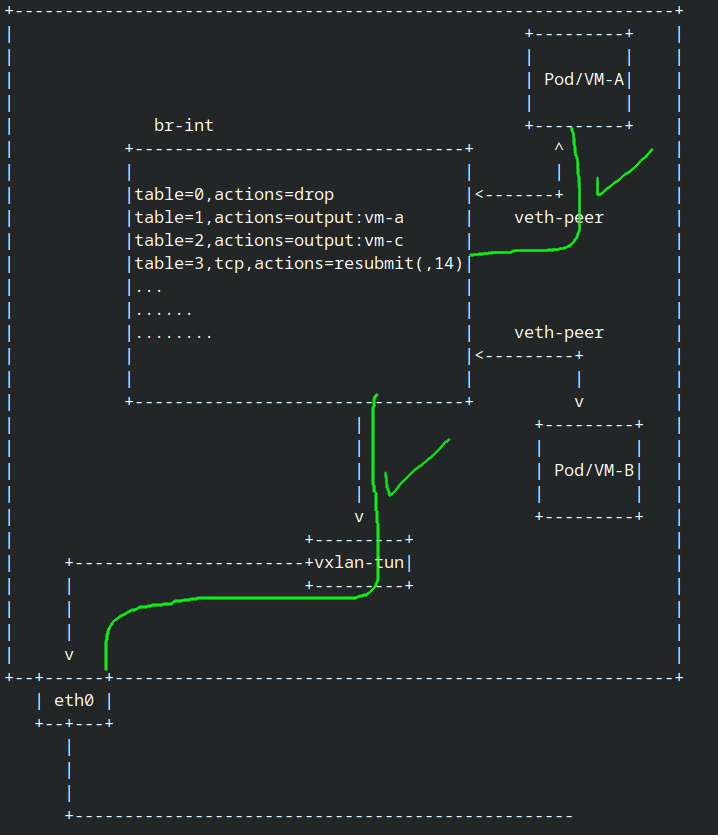
until now we can trace the incoming package into br-int or ovs, now how to trace the package was truely forward it into tunnel network or droped in br-int?
let’s use ovs_vport_send.
just replace ovs_vport_receive with ovs_vport_send
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
#include <linux/skbuff.h>
#include <linux/ip.h>
#include <linux/udp.h>
#include <linux/socket.h>
#include "openvswitch-module/vport.c"
BEGIN
{
printf("Tracing ovs_vport_send rev. Hit Ctrl-C end.\n");
}
kprobe:ovs_vport_send {
$vport = (struct vport *)arg0;
$skb = (struct sk_buff *)arg1;
$dev = (struct net_device *)$vport->dev;
$iph = (struct iphdr*) ($skb->head + $skb->network_header);
if ($iph->protocol == IPPROTO_ICMP) {
if (($iph->saddr == (uint32)pton("10.16.0.28")) && ($iph->daddr == (uint32)pton("10.16.0.29"))) {
$src_ip = ntop (AF_INET, $iph->saddr);
$dst_ip= ntop (AF_INET, $iph->daddr);
printf("iface_name: %s src_ip:%s -> dst_ip:%s \n",$dev->name, $src_ip,$dst_ip);
}
}
}
END
{
printf("OVER bye!!")
}
Run it

so the interface name was genev_sys_6081 which is the tunnel interface and that mean the pkt was done processed by ovs and now the pkt delevery into dst node who run netshoot-2
OK now we can trace pkt from incoming the veth peer interface until exit via tunnel, but how if the pkt was dropped in ovs? let’s try it.
To run this scenario i need create network policy who block all ingress and egress from&to pod netsoot-1.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
cat <<EOF | kubectl create -f -
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata:
name: network-policy
namespace: default
spec:
podSelector:
matchLabels:
app: netshoot-1
policyTypes:
- Ingress
- Egress
EOF
Run the code

As you can see the bpftrace was stopped print that mean the pkt was stopped or dropped in ovs since i apply the network policy, but if i run the bpftrace with ovs_vport_receive it’s should still showing the pkt or the pkt still coming into ovs from netsoot-1.
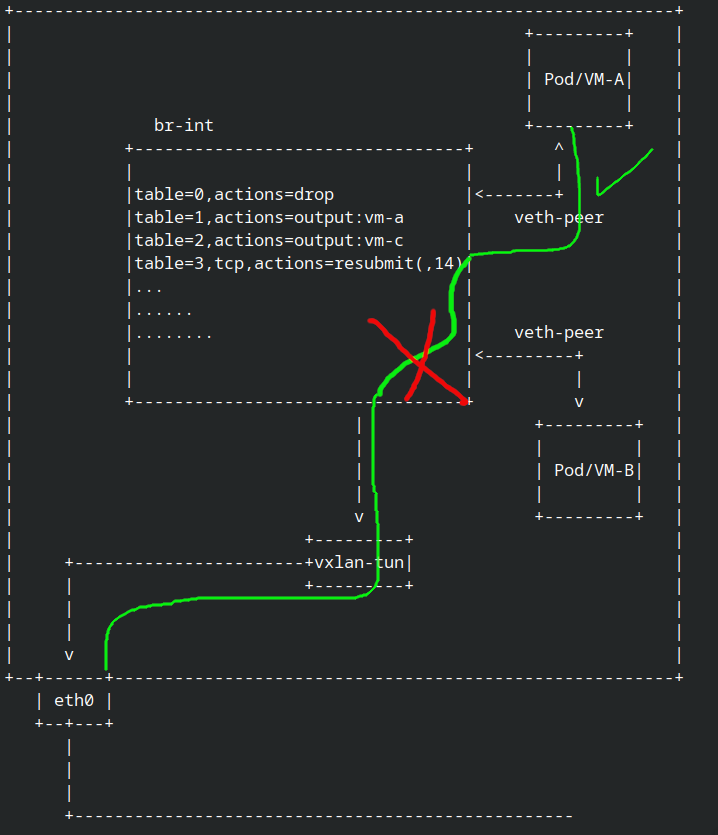
this is just a little example of tracing ovs with ebpf, we can create more advance tracing with ebpf map for example or we can create a metrics exporter for monitoring thr datapath.
Comments powered by Disqus.