Deploy Ceph Rgw with Production Grade

ughhhh, post kali ini kayaknya bakal pake bahasa indonesia aja, lagi malas pake b.enggress wkwkwkwk dan yang bahas ceph dalam bahasa indonesia masih sedikit (ya iyalah, wong yang pake aja pada sembunyi sembuyi wkwkwkw)
seperti judulnya kali ini saya bakal ngebahas “cara deploy ceph radosgw/s3 diprod”, sejujurnya ini pengalaman pertama deploy ceph buat prod apalagi s3 biasanya sih cuman buat rbd doang biar bisa dipake openstack. eh tapi saya sendiri sudah lumayan lama maen maen ama ceph, mulai awal maen kira kira di tahun 2018 dan mulai in depthnya itu sekitar tahun 2021-2023 jadi udah lumayan tau lah “rule rule” didalam ceph.
ok daripada kelamaan too much texto mending langsung gass, okgass? bukan kampanye paslon no 2
Env
pertama sih harus tau environmentnya dulu, istilahnya beda tempat beda rasa kalau di env saya itu
- 5 node
- 4 ssd (3.5T per disk)
- 31+ hdd (20T per disk)
- network public 25G
- network cluster 100G
Network
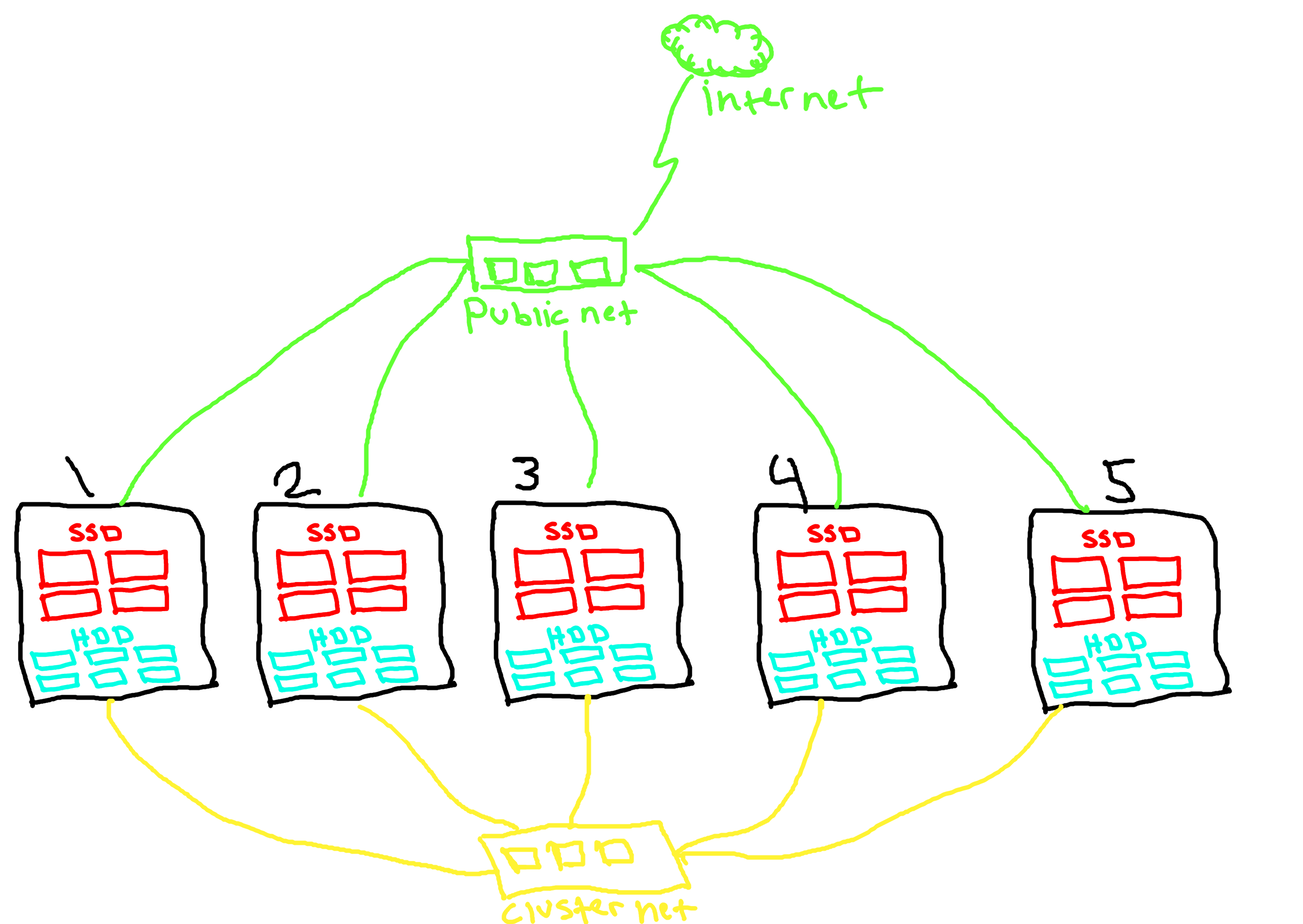
Kurang lebih topologynya kaya begini, mak kau hijau itu public network dan tersambung dengan outside(internet) sedangkan kuning itu cluster network, jadi mau tidak mau harus pake 2 nic (pake vlan bisa, tapi pastikan peformance nicnya besar).
hal yang penting disini adalah jumbo frame untuk masalah bonding/vlan/mlag/bgp/etc saya serahkan kepada kemampuan individu.
dari topology ini ada 5 node nah dari 5 node tersebuh nanti kita ambil 3 buat ceph-mon/mgr/mds/rgw jadi kita ambil node1,node2,node3 sebagai ‘controller’ ceph kita
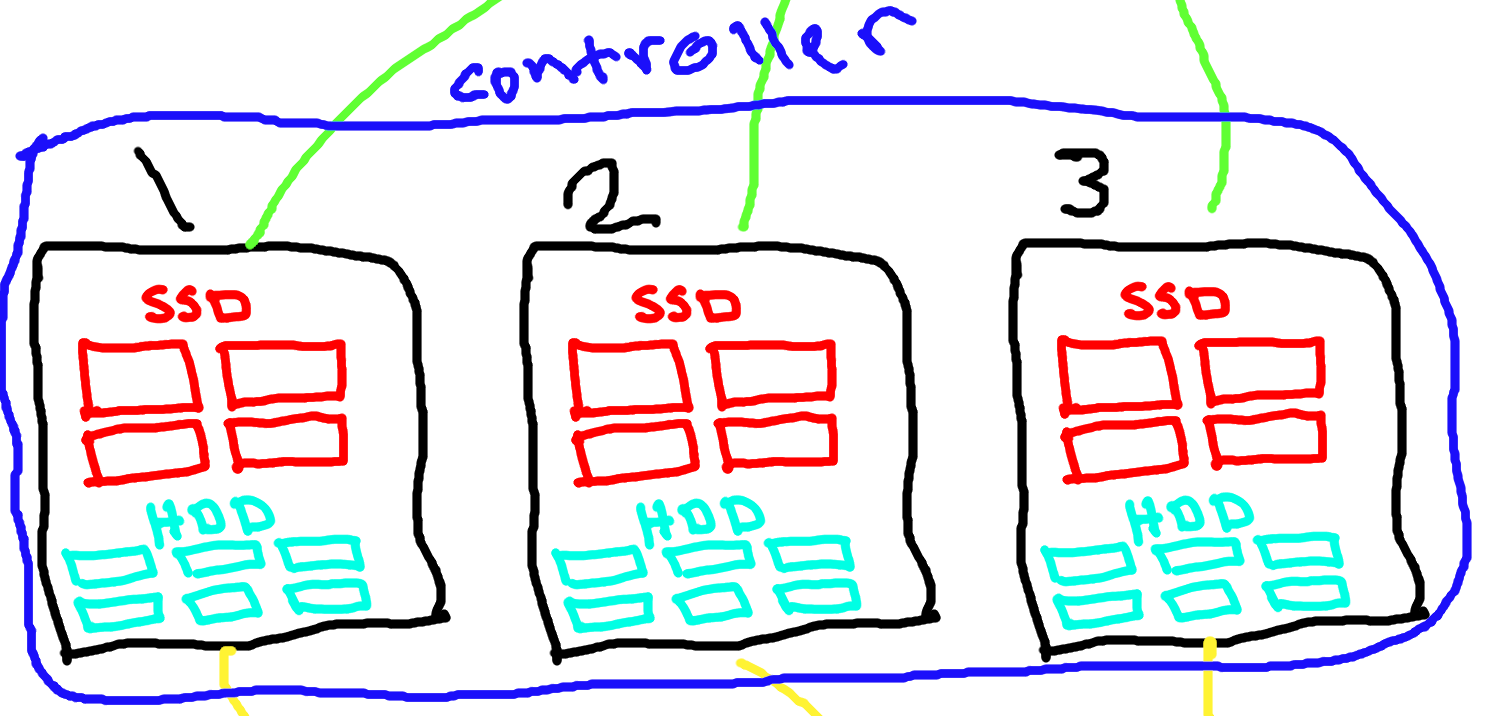
Sebenernya engga harus 3 tapi lebih baik kalau 3 atau 5 yang penting jumlah controller itu ganjil dikarenakan ceph pake paxos algo buat nentuin leadernya
Storage
disini saya punya 2 disk type ssd dan hdd, tentu saja size ssd jauh lebih kecil daripada hdd dan juga performance hdd jauh lebih lambat dari ssd
karena goal dari cluster ini adalah ‘size storage’ jadi saya dan tim memutuskan untuk membuat ssd sebagai cacheing device (untuk hal lebih dalam tentang cacheing device bisa cek post saya yang lainnya) recana awal saya ingin membuat 1 ssd/cache dev dapat menghandle 8 (32/4 = 8) hdd/back dev tetapi setelah saya ingat ingat bahwa writeback mode sangat riskan jika dijalankan dengan beberapa backing device/hdd sempat terpikir untuk memakai writethrough atau writearound mode tapi jika dibandingkan dengan writeback kedua mode tersebut mempunyai performance yang sangat jauh
diakhir saya tetap memutuskan menggunakkan writeback sebagai cacheing mode tetapi dengan raid 1 ssd

Writeback memang berbahaya jika digunnakan dengan multiple hdd/backing dev dikarenakan jika ssd/cache dev rusak maka semua hdd/backing dev yang terattach kesana akan tidak bisa terbaca. maka dengan rule tersebut saya melakukan sedikit engginering, jika saya menggunakan raid1 pada ssd/cache dev maka tidak akan berdampak langsung kepada hdd/backing dev
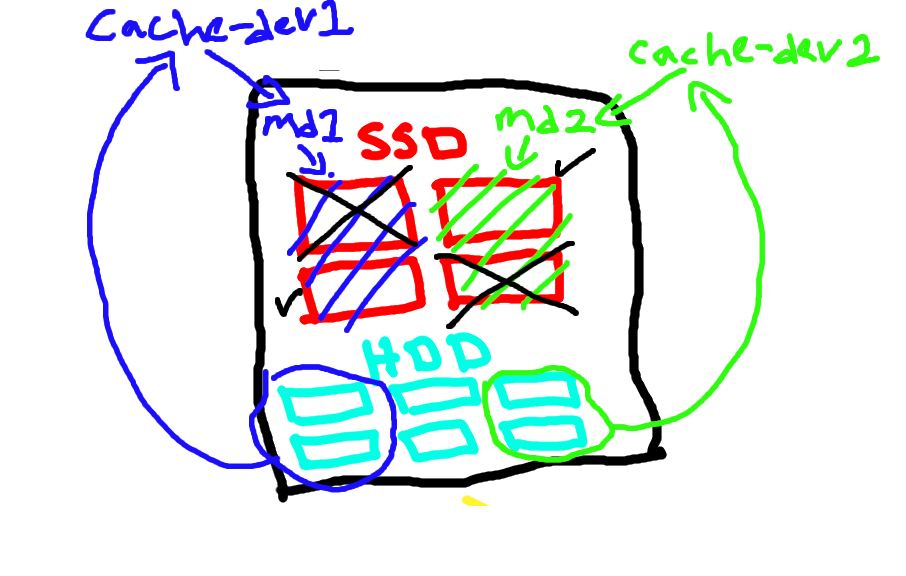
owh iya, dikarenakan saya menggunakan raid1 pada ssd/cache dev maka sekarang saya hanya memiliki logical 2 ssd kan? maka dari itu 1 ssd akan menghandle sekitar 15/16 hdd
setup raid1
1
2
3
mdadm --create /dev/md1 --level=raid1 --raid-devices=2 /dev/X /dev/Y
mdadm --create /dev/md2 --level=raid1 --raid-devices=2 /dev/V /dev/Z
cat /proc/mdstat ## Tunggu sampai sync block selesai
setup bcache
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
make-bcache --block 4k --bucket 2M -C /dev/md1
make-bcache --block 4k --bucket 2M -C /dev/md2
UUID_CACHE_1=$(bcache-super-show /dev/md1 | grep cset | grep -oE "[0-9a-f]{8}-[0-9a-f]{4}-[0-9a-f]{4}-[0-9a-f]{4}-[0-9a-f]{12}")
UUID_CACHE_2=$(bcache-super-show /dev/md2 | grep cset | grep -oE "[0-9a-f]{8}-[0-9a-f]{4}-[0-9a-f]{4}-[0-9a-f]{4}-[0-9a-f]{12}")
ITER=0
for i in $(lsblk | grep <DISK SIZE> | grep -v bcache | awk '{print $1}')
do
echo "Create bcache $ITER /dev/$i";
wipefs -a /dev/$i
make-bcache --block 4k --bucket 2M -B /dev/$i --wipe-bcache
sleep 1
if (( $ITER <= 15 ));
then
echo $UUID_CACHE_1 > /sys/block/bcache$ITER/bcache/attach
else
echo $UUID_CACHE_2 > /sys/block/bcache$ITER/bcache/attach
fi
echo writeback > /sys/block/bcache$ITER/bcache/cache_mode
ITER=$(expr $ITER + 1)
done;
berikut full diagram
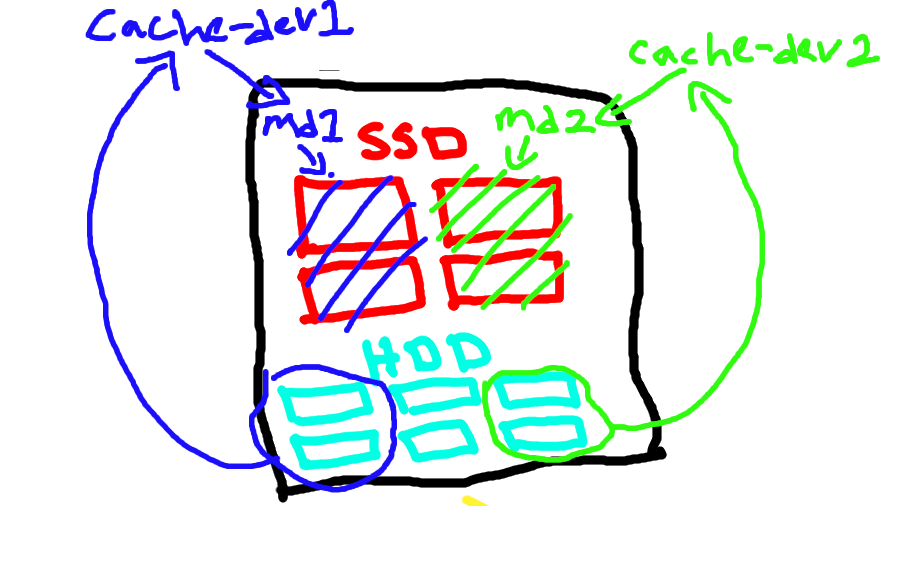
bash
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
root@jk1-xxxxxx:/home/xxxxxxx/s3-benchmark# lsblk | grep -v ceph
NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINTS
loop0 7:0 0 63.9M 1 loop /snap/core20/2105
loop1 7:1 0 63.9M 1 loop /snap/core20/2318
loop3 7:3 0 87M 1 loop /snap/lxd/28373
loop4 7:4 0 40.4M 1 loop /snap/snapd/20671
loop5 7:5 0 38.8M 1 loop /snap/snapd/21759
loop6 7:6 0 87M 1 loop /snap/lxd/29351
sda 8:0 0 20T 0 disk
└─bcache0 252:0 0 20T 0 disk
sdb 8:16 0 20T 0 disk
└─bcache1 252:128 0 20T 0 disk
sdc 8:32 0 20T 0 disk
└─bcache2 252:256 0 20T 0 disk
sdd 8:48 0 20T 0 disk
└─bcache3 252:384 0 20T 0 disk
sde 8:64 0 20T 0 disk
└─bcache4 252:512 0 20T 0 disk
sdf 8:80 0 20T 0 disk
└─bcache5 252:640 0 20T 0 disk
sdg 8:96 0 20T 0 disk
└─bcache6 252:768 0 20T 0 disk
sdh 8:112 0 20T 0 disk
└─bcache7 252:896 0 20T 0 disk
sdi 8:128 0 20T 0 disk
└─bcache8 252:1024 0 20T 0 disk
sdj 8:144 0 20T 0 disk
└─bcache9 252:1152 0 20T 0 disk
sdk 8:160 0 20T 0 disk
└─bcache10 252:1280 0 20T 0 disk
sdl 8:176 0 20T 0 disk
└─bcache11 252:1408 0 20T 0 disk
sdm 8:192 0 20T 0 disk
└─bcache12 252:1536 0 20T 0 disk
sdn 8:208 0 20T 0 disk
└─bcache13 252:1664 0 20T 0 disk
sdo 8:224 0 20T 0 disk
└─bcache14 252:1792 0 20T 0 disk
sdp 8:240 0 20T 0 disk
└─bcache15 252:1920 0 20T 0 disk
sdq 65:0 0 3.5T 0 disk
└─md1 9:1 0 3.5T 0 raid1
├─bcache0 252:0 0 20T 0 disk
├─bcache1 252:128 0 20T 0 disk
├─bcache2 252:256 0 20T 0 disk
├─bcache3 252:384 0 20T 0 disk
├─bcache4 252:512 0 20T 0 disk
├─bcache5 252:640 0 20T 0 disk
├─bcache6 252:768 0 20T 0 disk
├─bcache7 252:896 0 20T 0 disk
├─bcache8 252:1024 0 20T 0 disk
├─bcache9 252:1152 0 20T 0 disk
├─bcache10 252:1280 0 20T 0 disk
├─bcache11 252:1408 0 20T 0 disk
├─bcache12 252:1536 0 20T 0 disk
├─bcache13 252:1664 0 20T 0 disk
├─bcache14 252:1792 0 20T 0 disk
└─bcache15 252:1920 0 20T 0 disk
sdr 65:16 0 3.5T 0 disk
└─md1 9:1 0 3.5T 0 raid1
├─bcache0 252:0 0 20T 0 disk
├─bcache1 252:128 0 20T 0 disk
├─bcache2 252:256 0 20T 0 disk
├─bcache3 252:384 0 20T 0 disk
├─bcache4 252:512 0 20T 0 disk
├─bcache5 252:640 0 20T 0 disk
├─bcache6 252:768 0 20T 0 disk
├─bcache7 252:896 0 20T 0 disk
├─bcache8 252:1024 0 20T 0 disk
├─bcache9 252:1152 0 20T 0 disk
├─bcache10 252:1280 0 20T 0 disk
├─bcache11 252:1408 0 20T 0 disk
├─bcache12 252:1536 0 20T 0 disk
├─bcache13 252:1664 0 20T 0 disk
├─bcache14 252:1792 0 20T 0 disk
└─bcache15 252:1920 0 20T 0 disk
sds 65:32 0 3.5T 0 disk
└─md2 9:2 0 3.5T 0 raid1
├─bcache16 252:2048 0 20T 0 disk
├─bcache17 252:2176 0 20T 0 disk
├─bcache18 252:2304 0 20T 0 disk
├─bcache19 252:2432 0 20T 0 disk
├─bcache20 252:2560 0 20T 0 disk
├─bcache21 252:2688 0 20T 0 disk
├─bcache22 252:2816 0 20T 0 disk
├─bcache23 252:2944 0 20T 0 disk
├─bcache24 252:3072 0 20T 0 disk
├─bcache25 252:3200 0 20T 0 disk
├─bcache26 252:3328 0 20T 0 disk
├─bcache27 252:3456 0 20T 0 disk
├─bcache28 252:3584 0 20T 0 disk
├─bcache29 252:3712 0 20T 0 disk
├─bcache30 252:3840 0 20T 0 disk
└─bcache31 252:3968 0 20T 0 disk
sdt 65:48 0 3.5T 0 disk
└─md2 9:2 0 3.5T 0 raid1
├─bcache16 252:2048 0 20T 0 disk
├─bcache17 252:2176 0 20T 0 disk
├─bcache18 252:2304 0 20T 0 disk
├─bcache19 252:2432 0 20T 0 disk
├─bcache20 252:2560 0 20T 0 disk
├─bcache21 252:2688 0 20T 0 disk
├─bcache22 252:2816 0 20T 0 disk
├─bcache23 252:2944 0 20T 0 disk
├─bcache24 252:3072 0 20T 0 disk
├─bcache25 252:3200 0 20T 0 disk
├─bcache26 252:3328 0 20T 0 disk
├─bcache27 252:3456 0 20T 0 disk
├─bcache28 252:3584 0 20T 0 disk
├─bcache29 252:3712 0 20T 0 disk
├─bcache30 252:3840 0 20T 0 disk
└─bcache31 252:3968 0 20T 0 disk
sdu 65:64 0 20T 0 disk
└─bcache16 252:2048 0 20T 0 disk
sdv 65:80 0 20T 0 disk
└─bcache17 252:2176 0 20T 0 disk
sdw 65:96 0 20T 0 disk
└─bcache18 252:2304 0 20T 0 disk
sdx 65:112 0 20T 0 disk
└─bcache19 252:2432 0 20T 0 disk
sdy 65:128 0 20T 0 disk
└─bcache20 252:2560 0 20T 0 disk
sdz 65:144 0 20T 0 disk
└─bcache21 252:2688 0 20T 0 disk
sdaa 65:160 0 20T 0 disk
└─bcache22 252:2816 0 20T 0 disk
sdab 65:176 0 20T 0 disk
└─bcache23 252:2944 0 20T 0 disk
sdac 65:192 0 20T 0 disk
└─bcache24 252:3072 0 20T 0 disk
sdad 65:208 0 20T 0 disk
└─bcache25 252:3200 0 20T 0 disk
sdae 65:224 0 20T 0 disk
└─bcache26 252:3328 0 20T 0 disk
sdaf 65:240 0 20T 0 disk
└─bcache27 252:3456 0 20T 0 disk
sdag 66:0 0 20T 0 disk
└─bcache28 252:3584 0 20T 0 disk
sdah 66:16 0 20T 0 disk
└─bcache29 252:3712 0 20T 0 disk
sdai 66:32 0 20T 0 disk
└─bcache30 252:3840 0 20T 0 disk
sdaj 66:48 0 20T 0 disk
└─bcache31 252:3968 0 20T 0 disk
nvme1n1 259:0 0 476.9G 0 disk
├─nvme1n1p1 259:2 0 1G 0 part /boot/efi
├─nvme1n1p2 259:3 0 1G 0 part /boot
└─nvme1n1p3 259:4 0 474.9G 0 part
└─md0 9:0 0 474.8G 0 raid1
├─md0p1 259:6 0 16G 0 part [SWAP]
└─md0p2 259:7 0 458.8G 0 part /
nvme0n1 259:1 0 476.9G 0 disk
└─nvme0n1p1 259:5 0 476.9G 0 part
└─md0 9:0 0 474.8G 0 raid1
├─md0p1 259:6 0 16G 0 part [SWAP]
└─md0p2 259:7 0 458.8G 0 part /
root@jk1-xxxxxx:/home/xxxxxxxx/s3-benchmark#
Deploy
setelah network dan storage terconfig mari kita mulai setup cephnya
ansible -i /etc/hosts all -m raw -a 'apt update;curl -s https://get.docker.com | bash'mkdir -p /opt/cephadm;cd /opt/cephadmcurl --silent --remote-name --location https://github.com/ceph/ceph/raw/quincy/src/cephadm/cephadmchmod +x cephadm./cephadm add-repo --release reef./cephadm installcephadm install ceph-commonmkdir -p /etc/cephcephadm bootstrap --mon-ip <PUBLIC_NETWORK/24> --cluster-network <PRIVATE_NETWORK/24>ssh-copy-id -f -i /etc/ceph/ceph.pub Xceph orch host add Xceph orch apply mgr --placement="3 node-1 node-2 node-3"ceph orch daemon add osd node-1:/dev/bcacheX
atau bisa pakai script, disini saya menghidari menggunakkan add-all device agar osd.idnya berurutan
1
2
3
4
5
6
7
8
9
10
11
12
13
14
for k in {1..5}
do
compute="node$k"
echo "Add osd on compute $compute"
osd_len=$(ceph orch device ls $compute | grep bcache | awk '{print $2}' | wc -l)
osd_len=$((osd_len-1))
for i in $( eval echo {0..$osd_len} );
do
bcache_dev=/dev/bcache$i
echo "Add $bcache_dev"
ceph orch daemon add osd $compute:$bcache_dev
done
done
sekarang seharusnya ceph sudah health_ok, selanjutnya kita coba deploy si rgw untuk si s3nya
nano rgw.ceph-s3.yaml
1
2
3
4
5
6
7
8
9
10
11
12
13
service_type: rgw
service_id: ceph-s3
placement:
hosts:
- node1
- node2
- node3
spec:
rgw_realm: Indonesia
rgw_zonegroup: Jakarta
rgw_zone: jakpus
rgw_frontend_type: "beast"
rgw_frontend_port: 8080
ceph orch apply -i rgw.ceph-s3.yamlceph orch ps
dan tunggu sampai service rgw.ceph-s3 up semua
btw kalau ingin si rgw pakai virtual bucket style bisa enable ini
ceph config set client.rgw rgw_dns_name s3.ceph.idceph config set client.rgw rgw_resolve_cname true
untuk pengaturan bucket atau user bisa dicoba via dashboard karena lebih mudah lewat dashboard.
Performance
kalau sudah ngobrol tentang deploy pasti ujung ujungnya bahas Performance.
Untungnya sedari awal deploy saya sudah melakukan fio test secara bertahap disetiap device yang di config
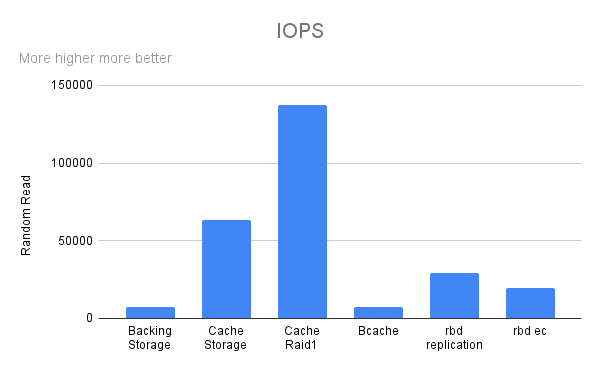
Random Read
IOPS
Bandwidth
.png)
Latency
.png)
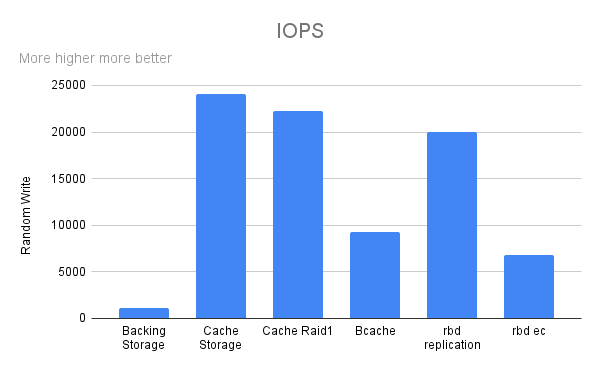
Random Write
IOPS
Bandwidth
.png)
Latency
.png)
Seperti dugaan saya, backing storage(hdd) memiliki Performance yang sangat jauh dibanding dengan Cache Storage(ssd) dan ssd raid 1 tetapi dengan menggabungkan mereka dengan bcache terlihat sedikit peningkatan
dan hasil akhir setelah menjadi ceph volume ternyata jauh lebih cepat daripada bcache device itu sendiri tapi hanya pada replicate rule tidak dengan erasure coding
untuk full output bisa dilihat disini
Comments powered by Disqus.